
Defining local page indexes
Pages indexes allow searching through the content of website pages. The indexes only cover pages within the Xperience content tree. Any pages without a representation in the content tree are NOT included (e.g. pages served by custom routes implemented only on the side of the live site application). The indexing mechanism and included content depends on the configuration of individual page types.
To set up Pages indexes, you need to perform both of the following tasks:
- Configure suitable search options for your site’s page types
- Specify the content for individual indexes
You can create multiple indexes for different sections of your website and use them as required in the implementation of your site’s search functionality.
Configuring page types for search
Different page types store different types of content. The system allows you to configure search indexing separately for each page type. The settings then apply to all search indexes that include pages of the given type.
To edit the search settings for page types:
- Open the Page types application.
- Edit a page type.
- Open the Search tab.
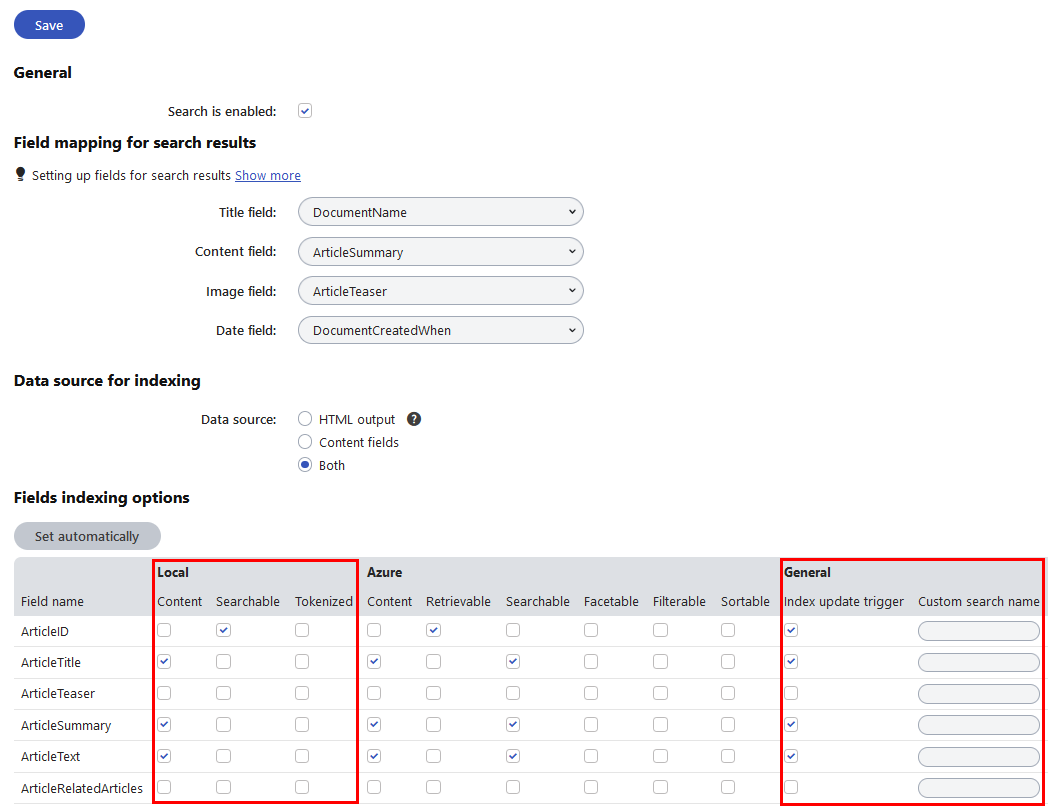
In the Field mapping for search results section, you can assign page fields to the most common parts of search results, such as the title, content extract or image. For detailed information, see Mapping fields for search results.
The Data source for indexing section allows you to select the overall indexing mechanism for the page type. Choose one of the following Data source options:
HTML output | Directly parses the HTML output of pages on the live site, which allows the search to find any text located on pages. Pages are indexed using a web crawler, based on the structure of the content tree in Xperience (pages without a representation in the content tree are NOT included). Recommendation: Use the HTML output source on sites that use content tree-based routing, for page types whose important content is created using the page builder. Tip: You can perform additional configuration and customization of the HTML output search crawler. |
Content fields | Indexes the structured content of pages in the content tree, which includes the following page data:
Content fields do NOT include the following:
Recommendation: Use the Content fields source for sections of the website where the important content is stored in page fields, such as products or structured articles. |
Both | Combines both HTML output and Content fields. Suitable for page types that store structured content in fields and also have other content in the page output (for example from the page builder or defined directly in the page code). |
The grid in the Fields indexing options section of the tab determines how the smart search indexes the page type’s fields (as defined on the Fields tab). Pages are often complex data structures with many different fields, and not all fields may be relevant to your search requirements. We recommend indexing only necessary fields to keep your indexes as small (and fast) as possible.
For locally stored search indexes, only the options under the Local and General sections of the grid apply (to learn about Azure Search page indexes, see Creating Azure Search indexes). You can set the following search options for individual fields:
Local | |
Content | If selected, the content of the field is indexed and searchable in the standard way. Within search indexes, the values of all fields with the Content option enabled are combined into a system field named _content (this field is used to find or filter matching search items, but is NOT suitable for reading and displaying human-readable information such as search result extracts). For the purposes of standard search, Content fields are automatically tokenized by the analyzer of the used search index. |
Searchable | If selected, the field is stored separately within indexes and its content can be searched using expressions in format: <field code name>:<searched phrase> See Smart search syntax for more information about field searches. Fields must be set as Searchable to be usable in search result filtering or ordering conditions. |
Tokenized | Relevant for Searchable fields. Indicates if the content of the field is processed by the analyzer when indexing. This allows the search to find results that match individual tokens (subsets) of the field’s value. If disabled, the search only returns items if the full value of the field exactly matches the search expression. If a field has both the Content and Searchable options enabled, the Tokenized option only affects the content used for field searches (content is always automatically tokenized for the purposes of standard search). |
General | |
Index update trigger | If selected, any modifications of the field’s value cause the system to update the given page in search indexes. We strongly recommend keeping this option enabled for Content and Searchable fields. For page types that use the HTML output (or Both) data source, enable the option if you wish to ensure that the search re-indexes the output of pages when an editor modifies the given field. |
Custom search name | Relevant for Searchable fields. The specified value is used as a substitute for the field code name in <field code name>:<searched phrase> search expressions. Note: If you enter a Custom search name value, the original field name cannot be used. |
After you Save changes of the field settings, you need to Rebuild all indexes that cover pages of the given type.
When running searches using page indexes, the system returns results according to the search settings of individual page types.
General page and SKU (product) fields
In addition to the fields of specific page types, you can configure the search settings for general page fields and E-commerce SKU (product) fields:
- Open the Modules application.
- Edit the E-commerce module.
- Open the Classes tab.
- Edit the SKU class.
- Select the Search tab.
- Click Customize.
You can configure the search settings just like for page types. The SKU fields are joined together with general page fields, such as fields that store the page name and metadata.
Important: The search settings of general fields affect all pages, even those that are not products.
Specifying the content of pages indexes
Page indexes only cover pages that are published on the live site.
To define which pages an index covers, define allowed or excluded content:
- Open the Smart search application.
- Select the Local indexes tab.
- Edit the index.
- Open the Sites tab and assign the sites where you wish to use the index.
- Switch to the Cultures tab and select which language versions of the website’s pages are indexed.
- At least one culture must be assigned for the index to be functional.
- Select the Indexed content tab.
- Click Add allowed content or Add excluded content.
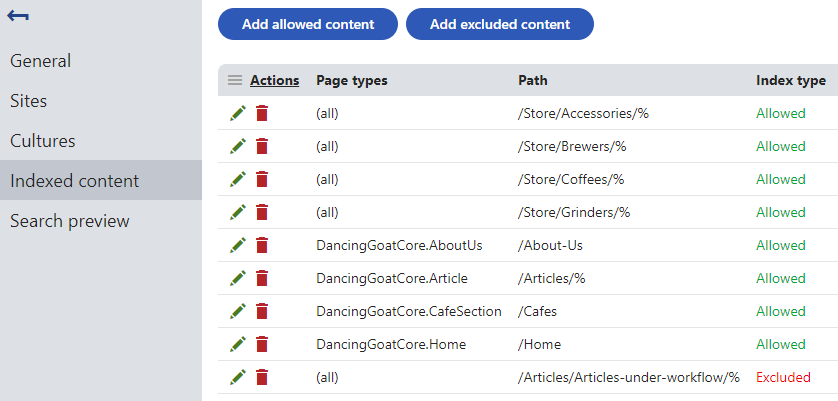
Allowed content defines which of the website’s pages are included in the index. Excluded content removes pages or entire website sections from the allowed content. Specify pages using a combination of the following options:
- Path – path expression identifying the allowed or excluded pages.
- Page types – allows you to limit which page types are included or excluded.
Examples
Content settings | Result |
| Includes or excludes all pages on the site. |
| Includes or excludes the /Partners page, without the child pages placed under it. |
| Includes or excludes all pages of the DancingGoat.Article page type on the entire site. |
| Includes or excludes all pages of the DancingGoat.Coffee and DancingGoat.Grinder page types found under the /Products section. |
Excluding individual pages from all indexes
You can also exclude specific pages from all smart search indexing:
- Open the Pages application.
- Select the given page in the content tree.
- In Edit mode, open the Properties -> General tab.
- Enable the Exclude from search property.
- Click Save.
The system also allows additional indexed content for pages whose page type uses the Content fields or Both data source for search (configured in the Page types application on the Search tab).
- Include attachment content – if selected, the index includes the text content of files attached to the specified pages. See Searching attachment files for more information.
- Include categories – if selected, the index stores the display names of Categories assigned to the specified pages. This allows users to find pages that belong to categories whose name matches the search expression.
Configuring the HTML output search crawler
The web crawler that indexes the HTML output of pages reads content under a user account. You can configure the user for every Pages index (on the General tab of the index editing interface):
Index property | Description |
User account for crawler | Sets the user account under which the crawler indexes pages. Only applies for pages whose page type has the HTML output or Both data source selected in the Page types application on the Search tab. Reading pages under a user allows the crawler to:
If empty, the index uses the user account specified in Settings -> System -> Default user ID (or the default administrator user account if the setting is empty). If you wish to assign a user to your search indexes, we recommend creating a dedicated service account with the appropriate permissions (not an account representing an actual live site user or editor). |
Excluding parts of HTML content
Xperience allows you to exclude specific parts of your page’s HTML output from search indexing (for page types that use the HTML output or Both data source for search). For example, excluding may be suitable for shared content within your site’s layout, such as a header or footer. Otherwise any search matches return results for all pages with the shared content.
To exclude HTML content from search indexing, wrap it within an HTML element marked with the data-ktc-search-exclude data attribute.
<div data-ktc-search-exclude>Content not processed by the search crawler</div>
Customizing how the crawler processes HTML
By default, the system converts the HTML output of pages to plain text before saving it to indexes. The processing includes the following modifications:
- Content is loaded only from the body element
- script and style tags are removed fully (including any content)
- All HTML and XML tag syntax is stripped
- All whitespace formatting is normalized to simple spaces
Developers can implement their own custom HTML output processing for the crawler.
If you customize the HTML output processing for the search crawler, you override and disable exclusion of content using the default data-ktc-search-exclude data attribute. If you wish to support content exclusion on the level of HTML code, your custom processing needs to reflect this attribute (or use your own exclusion pattern).
Start by preparing a separate project for custom classes in your Xperience solution (or use an existing one):
- Open your Xperience solution in Visual Studio.
- Add a custom assembly (Class Library project) with class discovery enabled to the solution.
- Reference the project from both the live site and Xperience administration (CMSApp) projects. See Applying customizations in the Xperience environment.
Next, create and register a custom implementation of the ISearchCrawlerContentProcessor service within the custom project:
- Add a new class under the custom project, implementing the ISearchCrawlerContentProcessor interface.
- Register the customization using the RegisterImplementation assembly attribute.
- Define the Process method:
- Access the raw page HTML code in the method’s htmlContent parameter.
- Perform all required processing.
- Return a string containing the result.
using CMS;
using CMS.Helpers;
using CMS.Search;
using AngleSharp.Html.Parser;
using AngleSharp.Html.Dom;
// Registers the custom 'ISearchCrawlerContentProcessor' implementation
[assembly: RegisterImplementation(typeof(ISearchCrawlerContentProcessor), typeof(CustomContentProcessor))]
public class CustomContentProcessor : ISearchCrawlerContentProcessor
{
public string Process(string htmlContent)
{
// Gets the body element from the HTML content, using the API of the AngleSharp library
var parser = new HtmlParser();
IHtmlDocument doc = parser.ParseDocument(htmlContent);
IHtmlElement body = doc.Body;
// Removes script tags
foreach (var element in body.QuerySelectorAll("script"))
{
element.Remove();
}
// Removes elements marked with the default Xperience exclusion attribute
foreach (var element in body.QuerySelectorAll($"*[{"data-ktc-search-exclude"}]"))
{
element.Remove();
}
// Gets the text content of the body element
string textContent = body.TextContent;
// Normalizes and trims whitespace characters
textContent = HTMLHelper.RegexHtmlToTextWhiteSpace.Replace(textContent, " ");
textContent = textContent.Trim();
return textContent;
}
}
If you do not wish to fully override the system’s default search content processor, but only add custom modifications:
- Get an instance of the default ISearchCrawlerContentProcessor service within your custom implementation (for example using dependency injection).
- Call the service’s Process method and modify the result as required.
public class CustomContentProcessor : ISearchCrawlerContentProcessor
{
private readonly ISearchCrawlerContentProcessor defaultSearchCrawlerContentProcessor;
public CustomContentProcessor(ISearchCrawlerContentProcessor defaultSearchCrawlerContentProcessor)
{
// Initializes an instance of the default ISearchCrawlerContentProcessor service
this.defaultSearchCrawlerContentProcessor = defaultSearchCrawlerContentProcessor;
}
public string Process(string htmlContent)
{
// Performs the default HTML content processing for the search crawler
string processedHtml = defaultSearchCrawlerContentProcessor.Process(htmlContent);
...
}
}
Remember to Rebuild all related page search indexes in the Smart search application after you apply your customization.